ElasticSearch 资源监控
前置条件
- 环境中存在ES服务
监控范围
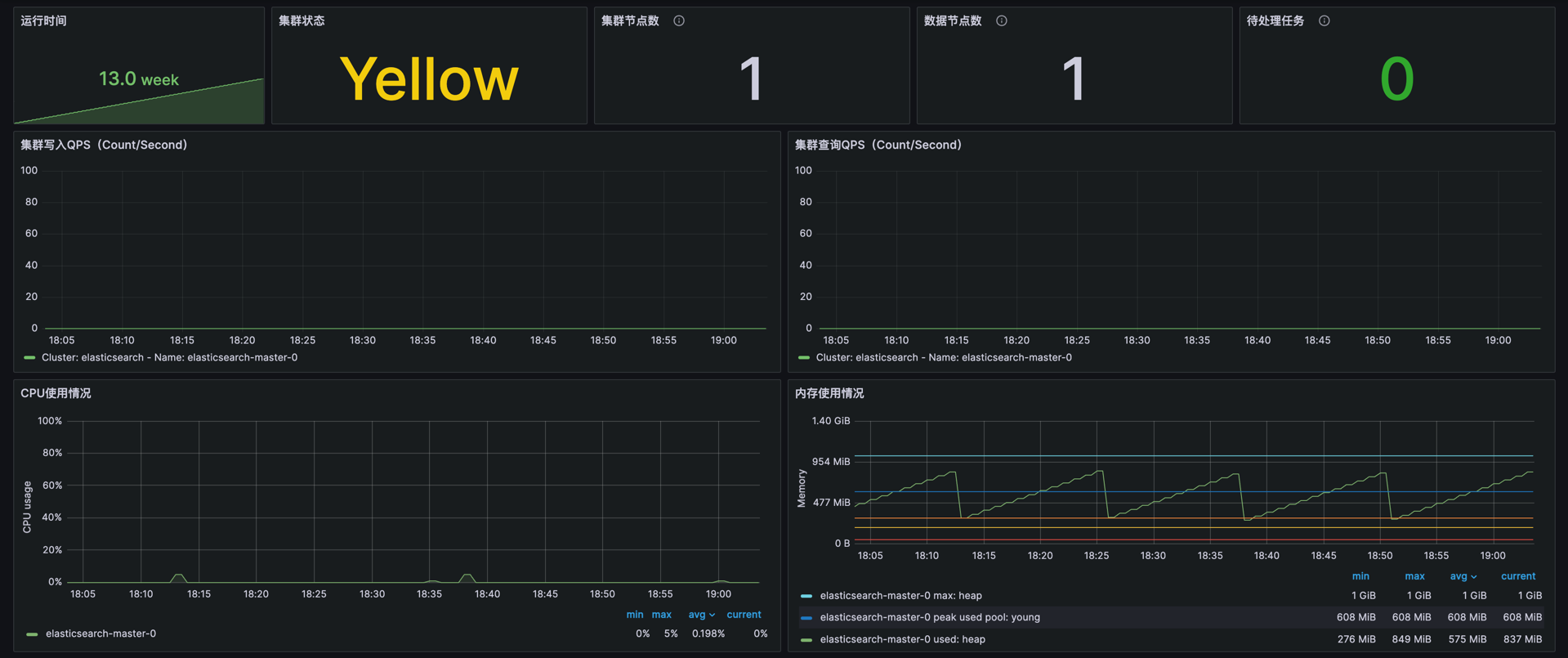
- 集群状态
elasticsearch_cluster_health_status{color="red"} == 1 or (elasticsearch_cluster_health_status{color="green"} == 1) + 1 or (elasticsearch_cluster_health_status{color="yellow"} == 1) + 2: 监控 Elasticsearch 集群的健康状态。用于监控集群的整体健康状况,并根据不同状态进行加权分析,帮助识别潜在的集群问题。elasticsearch_cluster_health_number_of_nodes:当前 Elasticsearch 集群中的节点总数。用于监控集群的规模和节点状态,确保所有节点都在正常运行。elasticsearch_cluster_health_number_of_data_nodes:当前 Elasticsearch 集群中的数据节点总数。确保集群中有足够的数据节点以处理数据分片和查询请求。
- 资源使用率
elasticsearch_process_cpu_percent:Elasticsearch 进程的 CPU 使用率(百分比)。用于监控 Elasticsearch 实例的 CPU 负载,帮助优化资源分配。elasticsearch_jvm_memory_used_bytes: Elasticsearch JVM 实例当前使用的内存(字节)。监控 JVM 内存使用情况,确保其不会因为内存不足导致性能下降或崩溃。
- 集群写入/查询QPS
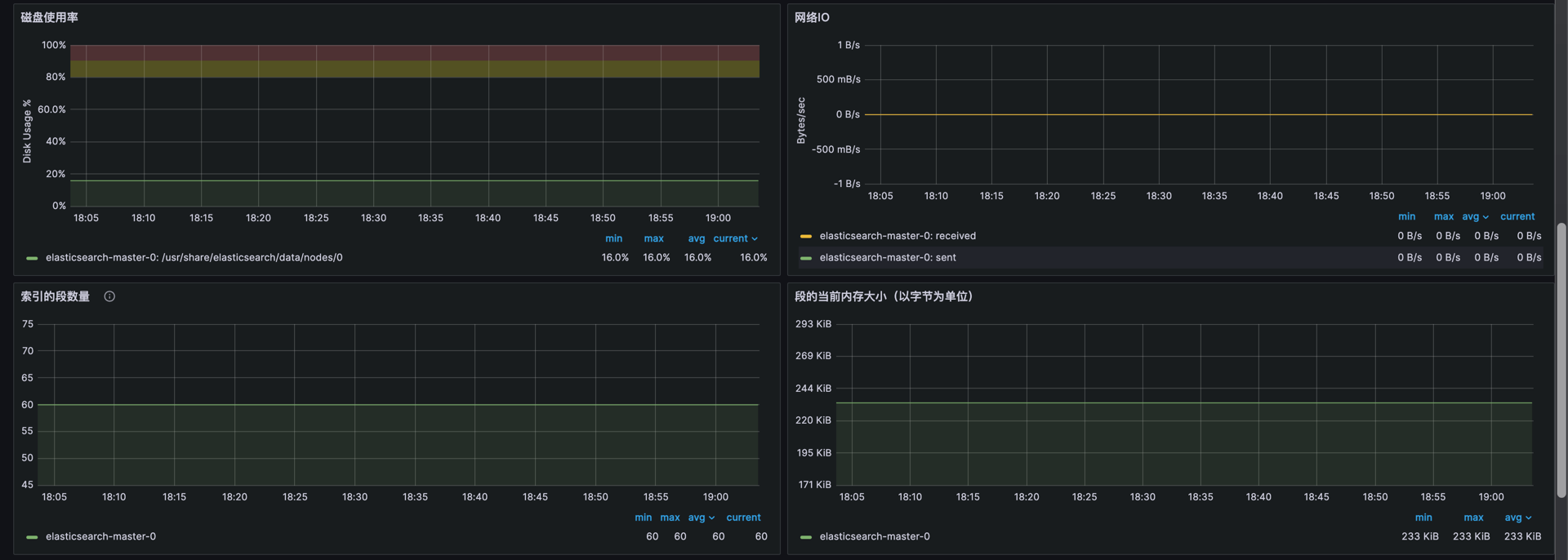
rate(elasticsearch_indices_indexing_index_total[1m]):计算每分钟 Elasticsearch 集群的写入请求数(Queries Per Second)。 用于监控集群的写入负载,帮助识别写入瓶颈。irate(elasticsearch_indices_search_query_total[5m]):计算每 5 分钟 Elasticsearch 集群的查询请求数(Queries Per Second)。监控集群的查询性能,帮助优化查询效率。1-(elasticsearch_filesystem_data_available_bytes/elasticsearch_filesystem_data_size_bytes):计算 Elasticsearch 文件系统的磁盘使用率。监控磁盘空间的使用情况,确保不会因为磁盘空间不足影响集群运行。irate(elasticsearch_transport_tx_size_bytes_total[$__rate_interval]):计算 Elasticsearch 集群传输层的出站流量速率(字节/秒)。监控网络传输性能,确保网络带宽不会成为瓶颈。irate(elasticsearch_transport_rx_size_bytes_total[$__rate_interval]):计算 Elasticsearch 集群传输层的入站流量速率(字节/秒)。用于分析入站流量,帮助识别可能的网络拥塞问题。
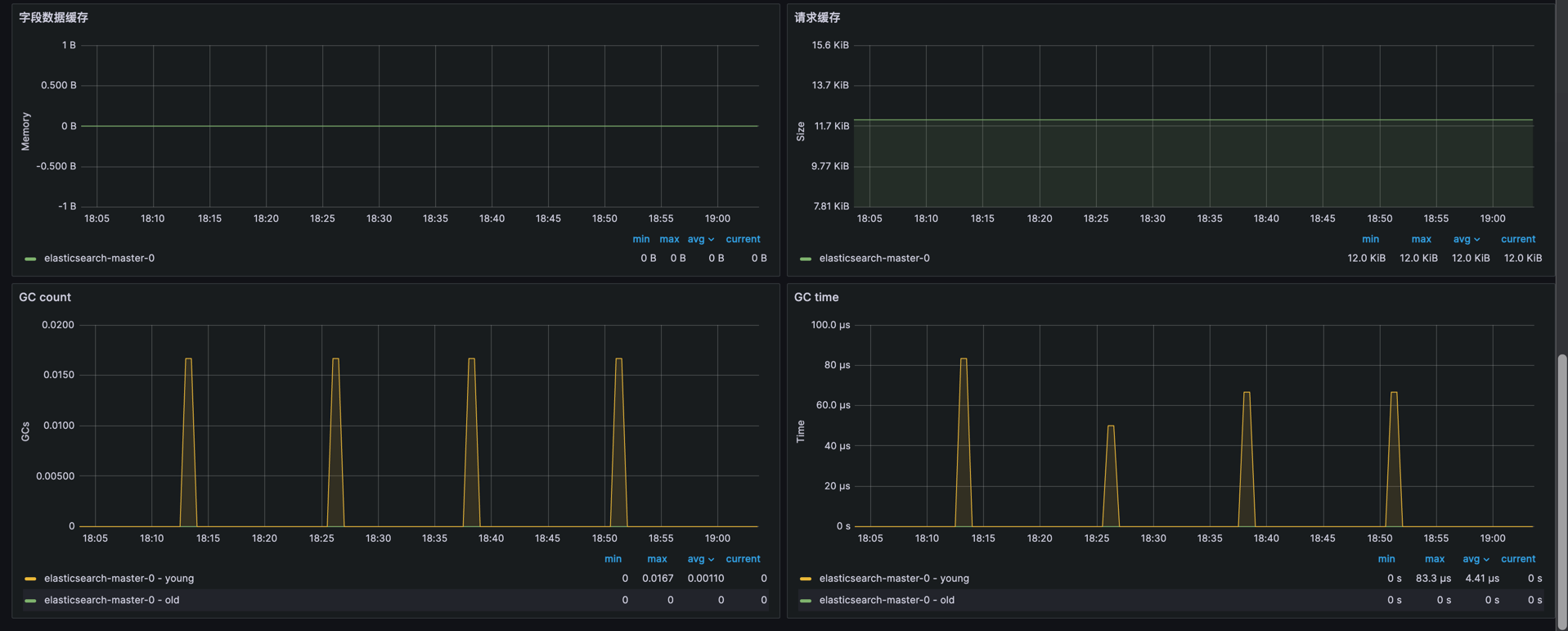
- 字段
elasticsearch_indices_segments_count:当前 Elasticsearch 集群中的段数。监控段的数量,以优化索引和搜索性能。elasticsearch_indices_segments_memory_bytes:Elasticsearch 集群中段的内存使用量(字节)。用于监控段的内存使用情况,帮助优化内存管理。elasticsearch_indices_fielddata_memory_size_bytes:Elasticsearch 集群中字段数据的内存使用量(字节)。用于监控字段数据的内存消耗,确保内存分配高效。elasticsearch_indices_request_cache_memory_size_bytes:Elasticsearch 请求缓存的内存使用量(字节)。用于优化请求缓存策略,帮助提升查询性能。
- GC
irate(elasticsearch_jvm_gc_collection_seconds_count[$__rate_interval]):计算 Elasticsearch JVM 实例垃圾回收次数的速率。用于监控垃圾回收频率,帮助优化内存管理。irate(elasticsearch_jvm_gc_collection_seconds_sum[$__rate_interval]):计算 Elasticsearch JVM 实例垃圾回收时间的总和速率。用于监控垃圾回收的耗时,确保 JVM 不会因为 GC 导致性能问题。
安装Exporter
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: elasticsearch-exporter
name: elasticsearch-exporter
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: elasticsearch-exporter
template:
metadata:
labels:
app: elasticsearch-exporter
spec:
containers:
- name: elasticsearch-exporter
image: registry.js.design/prometheus/elasticsearch-exporter:latest
args:
- '--es.uri=http://elastic:123.js@elasticsearch-master.infra:9200'
- '--es.all'
- '--es.timeout=30s'
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9114
name: metrics
securityContext:
privileged: false
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-exporter
namespace: monitoring
spec:
ports:
- port: 9114
targetPort: 9114
protocol: TCP
name: metrics
selector:
app: elasticsearch-exporterPrometheus 端点配置
固定端点
- job_name: 'ElasticSearch'
scrape_interval: 1m
static_configs:
- targets:
- elasticsearch-exporter.monitor:9114Kubernetes发现
- job_name: 'ElasticSearch'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
]
action: keep
regex: monitoring;elasticsearch-exporter监控大盘